欧博会员官网
亚新捕鱼网站加载速度慢_MySQL的索引,你真的有好好贯通过吗?

亚博真人百家乐
哈喽大家好!我是小三。今天咱们来讲索引。
索引是什么?「索引的见地」:索引是一种特地的文献(InnoDB数据表上的索引是表空间的一个构成部分),它们包含着对数据内外的整个记载的援用指针。粗造来说等于数据库索引就好像是一册书的目次,能够加速数据库的查询速率。
「索引的作用」:索引存在的目标等于在于进步查询恶果,使得原始的赶快全表扫描变成了快速规章锁定数据
高科技 常用的索引分类:1、夙昔索引:这是最基本的索引,莫得任何的死心
2、唯独索引:引列的值必须唯独,但允许有空值(翔实和主键不同)
奥斯卡赔率以多样化博彩游戏赛事直播博彩攻略技巧分享,广大博彩爱好者带来全面博彩知识最高博彩收益,您博彩游戏中大展身手。3、组合索引:多个数据列构成的索引,苦守了最左匹配原则
索引高性能保证:1、把查询流程中的赶快事件变成了规章事件
亚新捕鱼2、数据保存在磁盘上,而为了进步性能,每次又不错把一部分的数据读入内存来揣测,探询磁盘的本钱八成是探询内存的十万倍傍边。
3、研究到磁盘IO口舌常腾贵的操作,揣测机操作系统作念了一系列的优化,当进行一次IO时,不光把刻下磁盘的地址的数据也把相邻的数据也王人读取到内存的缓冲区之内。因为局部的预读性旨趣告诉了咱们,当揣测机探询一个地址的数据的时候,与它响铃的数据也会很快被探询到。每一次IO读取的数据咱们王人称之为一页(page)。具体一页会有多大的数据,这跟操作系统接洽,一般为4k或者是8k。
皇冠430 那为什么磁盘读取数据会很慢呢?咱们知说念磁盘读取工夫=寻说念工夫+旋转工夫+传输工夫,当需要从磁盘读取到数据的时候,系统会将数据的逻辑地址传给磁盘,磁盘的适度电路按照寻址逻辑将逻辑地址翻译成了物理地址,就信赖了要读的数据 在哪一个磁说念,哪个扇区。为了读取扇区的数据,需要将磁头放到扇区的上方,为了齐备这极少,磁头需要出动瞄准相应的磁说念,这个流程叫寻说念,在这里所滥用的工夫叫作念寻说念工夫,然后磁盘旋转筹备扇区旋转到磁头下,这个流程滥用的工夫叫作念旋转工夫。
索引的底层齐备决策咱们使用索引的目标,天然是要进步查询的恶果。举例像字典,如果要查询"mysql"这个单词,咱们率先信赖是要定位到m字母,然后从下往下找到y字母,依此类推。
索引的设想难度查询要求:等值查询,还有限度查询(>、<、between、in)、疲塌查询(like)、并集查询(or)
数据量:进步一千万数据通过索引查询,查询性能保证
常见的检索决策分析规章检索:最基本的查询算法-复杂度O(n),数据量大的话这个算法的恶果是倒霉的
二叉树查找:O(log2n),单层节点所能存储数据量较少,需要进行遍历多层才调拿到数据,归来点数k与高度h的关系为k=(2^h)-1

hash索引:无法欢畅限度查找,可是它的等值检索快,hash值==》物理地址x018,限度检索
B-Tree:每个节点王人是一个二元数组:[key,data],整个的节点王人不错存储数据,key为索引key,data为除除外的数据
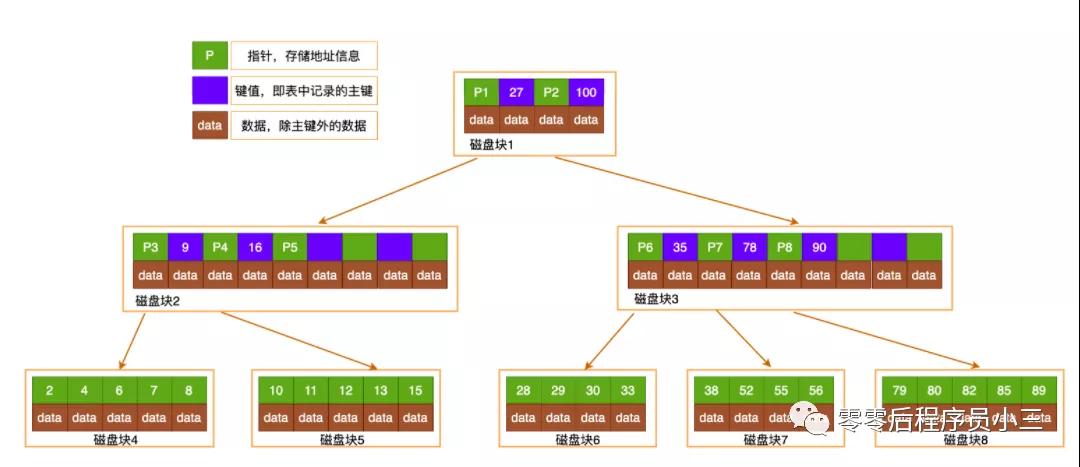
B+Tree数据结构高性能分解
B-Tree的过错:插入删除新的数据记载会迫害掉B-Tree的性质,因此在插入删除时,需要对树进行一个分裂、并吞、飘荡等操作来保握B-Tree的性质。在区间查找时可能需要复返表层节点从头,IO操作繁琐。
B+Tree的改革:非叶子节点不存储data,只存储了索引的key,只好叶子节点才存储data
皇冠信用盘登3出租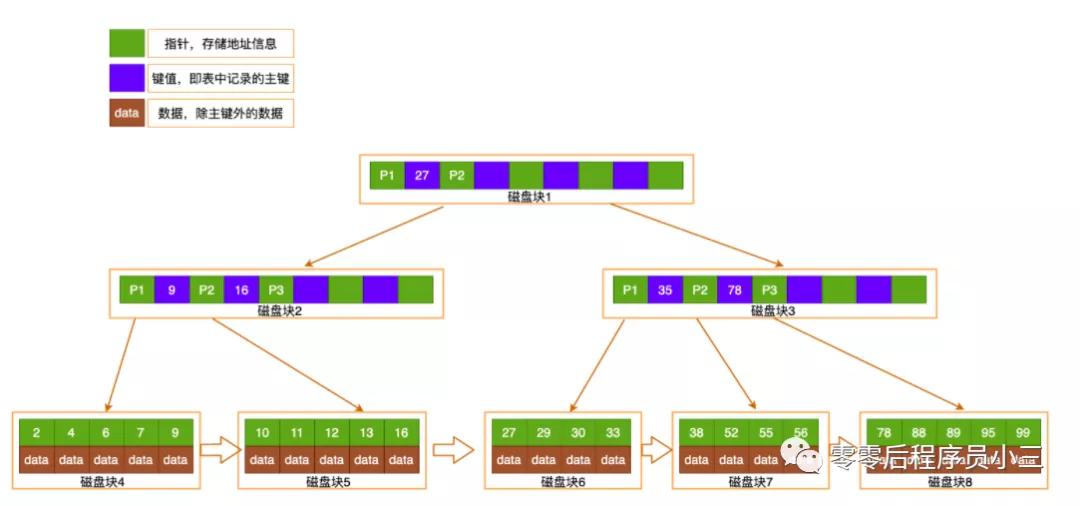
「高性能的保证」:
第一、3层的b+树不错暗示上百万的数据,如果上百万的数据查找只需要进行三次IO的话,那么对性能的进步无疑是雄伟的,如果莫得索引的话,欧博官网代理每个数据项王人要发生一次IO那么就会有百万次的IO,这彰着本钱相配相配高。
第二、在B+Tree的每个叶子节点加多一个指向相邻子节点的指针,这么就形成了带有规章探询指针的B+Tree
第三、B+Tree只在叶子节点来存储数据,整个的叶子节点包含一个链指针,其他内存的非叶子节点只存储索引数据。只期骗索引快速的定位数据索引限度,先定位索引再通过索引高效的定位数据。
网站加载速度慢 mysql为什么会选错索引 优化器的逻辑Mysql Server层的优化器细腻的是遴选索引,而优化器遴选索引的目标等于要找到一个最优的践诺决策,况且用最小代价来践诺语句。在数据库内部,扫描行数是影响践诺代价的身分之一。扫描的行数越少,也就意味着探询的磁盘的数据次数就越小,消耗的CPU就越少。扫描行数并不是唯独的判断法式,优化器还汇聚会了是否使用临时表、是否排序等等身分来概述判断。
扫描行数是怎样判断的Mysql在确切开动践诺语句之前,并不能以精准的知说念欢畅该查询条目的记载究竟有若干条,只可证实统计的信息来估算记载数。是以这个统计信息等于索引的“分离度”。彰着,一个索引上头的值不同得越多,这个索引的分离度就越好。在一个索引上不同值的个数,称为基数。
那么,mysql是怎样样得回索引基数的?在这里mysql采样统计本领,可是为什么要使用采样统计这种本领呢?原因等于因为如果把整张表取出来然后进行一溜行的统计,天然这么能够得回精准的数据,可是代价也太高了,是以的话只可使用采样统计。
#创建表 CREATE TABLE `test` ( `id` int(11) NOT NULL, `a` int(11) NOT NULL default 0, `b` int(11) NOT NULL default 0, PRIMARY KEY (`id`), KEY `a` (`a`), KEY `b` (`b`) ) ENGINE=InnoDB; #添加数据 delimiter ;; create procedure xddata() begin declare i int; set i=1; while(i<=100000)do insert into test values(i, i, i); set i=i+1; end while; end;; delimiter ; call xddata(); 数据查询 explain select * from test where (a between 1000 and 2000) and (b between 50000 and 100000) order by b limit 1;
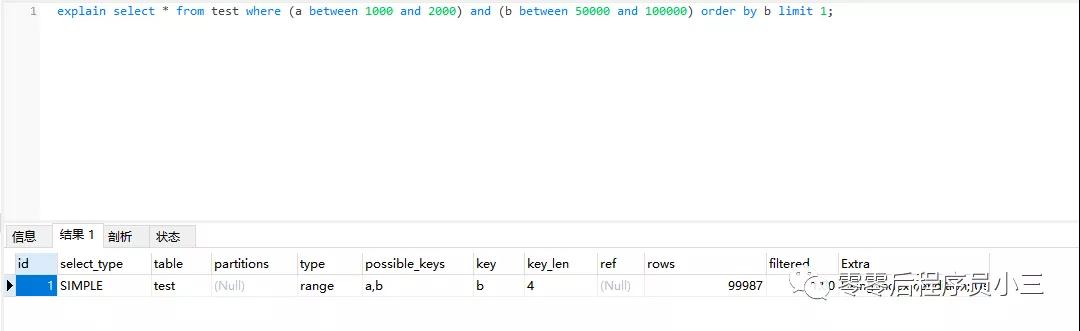
「为什么会出现这种驱散呢?」
在多个的索引情况下,优化器一般融会过相比了扫描行数、是否需要临时表以及是否需要排序等身分来手脚索引的半段依据。
遴选了索引b,则就需要在b索引上扫描9W笔记载,然后回到主键索引上过滤掉不欢畅a条目的记载,因为索引有序,是以使用b索引不需要独特排序。
「处罚决策」
使用force index a让mysql获胜遴选a索引来处理此处的查询
“今天巫山枝头,明天百姓桌上”。进入7月,一架架满载巫山脆李的“脆李专机”从重庆市巫山县飞往北上广深等各大城市。从去年的每天1班到今年的每天2班,运行周期由去年的15天增加到20天,“脆李专机”的“扩容”,既折射持续扩大的国内需求,也映照着经济运行整体回升向好态势。
zh皇冠信用盘登3出租那么如果你要在夏天穿裙子,最好就是用这种长度在脚踝上方的中长裙装,把我们的大腿赘肉直接给遮住,纤细的脚踝给露出来。
select * from test where (a between 1000 and 2000) and (b between 50000 and 100000) order by b limit 1; select * from test force index(a) where (a between 1000 and 2000) and (b between 50000 and 100000) order by b limit 1;
在其他的场景:
数据表有频频的删除或者是更新操作导致的数据缺乏形成的,形成的原因可能是分析器explain的驱散预估的rows值跟实际的情况差距相比大,分析器分析扫描行数用的是抽样侦探。统计分析分歧话不错使用analyze table test高歌,用来从头统计索引信息。
【口试题】唯独索引和夙昔索引的区别在哪?「1.查询上的区别」
皇冠客服飞机:@seo3687对唯独索引,由于索引界说了唯独性,查到第一个欢畅条目的记载之后,就会罢手检索。
对夙昔索引,查找到欢畅条目的第一个记载'ab'后,需要找下个记载,直到遇到第一个不欢畅k='ab'条目的记载
「2.修改上的区别」
关于唯独索引,整个更新操作要先判断该操作是否会违犯唯独性无间,唯独索引不会用change buff,若所修改的数据在内存当中,找到索引所对应的存储位置、判断到莫得突破,然后再插入值,语句践诺末端。若所修改的数据不在内存当中,则需要将数据页也读入内存,判断到莫得突破,再插入值,语句践诺末端。
「3.性能上的区别」
夙昔索引查找数据的时候会将适合条目的王人给查找出来
唯独索引主如若第一条适合条目的就会立即复返,不会在接续查找了,因为唯独的为数照旧确保了只好一条适合条目